|
|
|
|
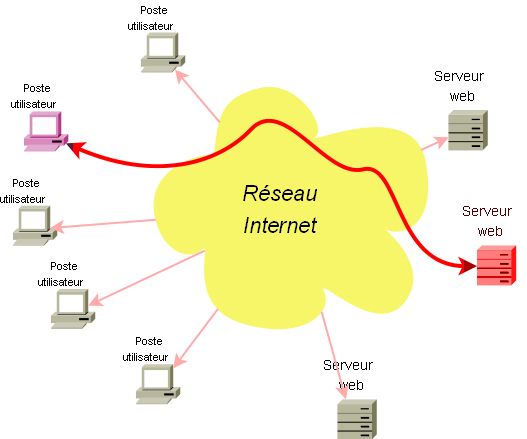
Le web est une application de l'Internet qui permet à tout utilisateur de se réseau de demander à un serveur de lui envoyer des informations.
Celles ci seront présentées à l'utilisateur par un logiciel spécifique : le navigateur.
Sur son poste de travail, l'accès au web se fait par un navigateur. Il en existe plusieurs, parmi ceux qui sont gratuits voici les plus utilisés :
Bien que les échanges entre serveur et navigateur soient standardisés par le W3C (World Wide Web Consortium) certains navigateurs prennent des libertés avec ces standards. Ainsi le rendu de certains éléments peut différer selon le navigateur utilisé.
De plus, comme ces logiciels sont en constante évolution, il en existe plusieurs versions.
Celle de Mozilla Firefox.
On trouve une présentation de fenêtre traditionnelle mais certains navigateurs récents ont une disposition pus dépouillée.
Dans notre exemple, outre les habituelles barres de titre et de menu, on trouve...
Ceci sera détaillé par la suite.
On peut aussi noter qu'il est possible de configurer le navigateur afin de ne pas afficher toutes ces barres. De plus, un panneau latéral à gauche peut être ouvert (il n'est pas présenté ci-dessus) pour afficher d'autres informations.
Par l'intermédiaire du navigateur, l'utilisateur demande à tel serveur web telle page. Le serveur transmet la page demandée au navigateur et celui-ci l'affiche.
L'utilisateur dispose de différents moyens pour demander l'adresse d'une page. Soit :
Dans tous les cas la barre d'adresse indique l'adresse effective de la page. On la nomme une URL (Uniform Resource Locator).
Voici, par un exemple, une URL (fictive) complète, beaucoup de ses composants peuvent être absents.
http://s2.tartempion.com:8080/vacances/2011/plage.html?id=12&ft=qsd#bateaux
En décomposant :
http: indique le protocole de communication entre le navigateur et le serveur. Les protocoles les plus courants sur le web sont HTTP (HyperText Transfert Protocol) et HTTPS où les échanges sont cryptés. Si cette information n'est pas donnée dans la barre d'adresses, le navigateur considère qu'il s'agit de "http:".
s2.tartempion.com identifie le serveur web qui contient l'information demandée. En l'occurrence ce serveur appartient au domaine : "tartempion.com". Depuis ce nom de domaine on peut trouver les personnes responsables du serveur.
:8080 indique le numéro de port d'entrée sur le serveur. Certains serveurs offrent différents services qui sont désignés par leur numéro de port. S'il est absent de l'URL, le port demandé est le 80.
/vacances/2011/plage.html est l'adresse de la page dans la structure de fichiers du serveur. Si cela n'est pas précisé, le serveur envoie une page par défaut dite "page d'accueil".
?id=12&ft=qsd sont des informations complémentaires transmises au serveur.
#bateaux indique, si présente, une position dans la page où le navigateur doit placer l'affichage. Si absente la page est affichée à partir du haut.
Exemples
| cnil.fr | Page d'accueil du site "Commission nationale de l'informatique et des libertés". |
| http://www.visugpx.com/ign/?lat=45.7716&lng=2.9628 | Affiche la carte IGN centrée sur le Puy de Dôme. |
| https://www.google.com/ | Version sécurisée du célèbre moteur de recherche web. |
| reports.internic.net/cgi/whois | Pour trouver les informations concernant les domaines Internet. |
| fr.wikipedia.org/wiki/Navigateur_web#Parts_de_march.C3.A9 | Parts de marché des navigateurs web dans la page consacrée à ces applications. |
Il est possible d'indiquer comme identification du serveur son adresse IP. Par exemple : http://209.85.148.103/ correspond à http://www.google.fr. Cela n'est utile que pour les rares sites qui ne disposent pas d'un nom de domaine.
Certains sites disposent d'adresses "raccourcies". Par exemple, en indiquant "meteo.fr" on voit l'adresse se développer pour atteindre la page d'accueil du site de Météo-France.
Pour certains sites dont l'accès est restreint on doit indiquer dans l'URL le nom de l'utilisateur et son mot de passe. Ces informations sont placées entre le protocole et l'identification du serveur. Cette méthode est en désuétude car le mot de passe est affiché en clair dans la fenêtre du navigateur.
Si l'adresse du serveur est fournie sous forme textuelle (nom de domaine), le navigateur demande la traduction en adresse IP à un serveur DNS (Domain Name Serveur).
Le navigateur commence par établir une liaison Internet avec le serveur puis le dialogue se fait selon le protocole précisé en début de l'URL. Généralement il s'agit de HTTP.
Il s'agit de demander au serveur la page à visualiser. Naturellement, sont aussi envoyés l'adresse de la connexion Internet de la machine de l'utilisateur (adresse IP) et le port de réception sur cette machine utilisé par le navigateur.
Mais d'autres informations sont aussi envoyées telles que l'indication de votre système d'exploitation et de votre navigateur (User-Agent) et, si vous avez cliqué sur un lien, l'adresse de la page où se trouvait ce lien (referer).
Le serveur commence par renvoyer des informations : "en-tête" qui indiquent, en particulier, si la requête a pu être satisfaite et sinon un code d'erreur. L'en-tête indique aussi, entre autres informations, la taille et la nature du contenu qui suit. Puis vient le contenu.
Un contenu de page web est habituellement écrit en HTML (il existe quelques variantes : XHTML, SVG...). HTML est un langage de description de page, il contient les textes à afficher, les informations concernant les liens éventuels de la page et les indications de mise en forme. Les autres composants de la page comme les images sont chargés ensuite par des requêtes spécifiques.
La page (HTML) peut contenir aussi des instructions de script. Elles seront exécutées par le navigateur pour rendre les pages plus interactives. Le langage de script le plus utilisé est Javascript. Par exemple les menus déroulants du haut de cette page fonctionnent grâce au JavaScript.
Il est possible de configurer le navigateur afin qu'il ne charge pas les images, ce qui est utile si le débit de transmission est limité. De même, on peut interdire l'exécution des séquences de script.
La richesse du web vient surtout de la possibilité d'intégrer dans la page des liens qui conduisent, en cliquant dessus, à d'autres pages du réseau. Là est l'origine du cette appellation anglaise "web" signifiant "toile d'araignée". Ainsi naviguer sur le web consiste à suivre les fils présentés par ces liens pour aller de pages en pages et de sites en site.
Il conviendrait, pour une navigation idéale, de pouvoir repérer facilement les liens dans la page et de savoir (avant de cliquer dessus) où ils conduisent : la cible. Hélas, il n'y a rien de certain sur ces sujets et cela est de la responsabilité du concepteur de la page. Il y a cependant quelques traditions.
Les liens peuvent être placés dans sur des mots du texte (lien hypertexte), sur des images, sur des boutons de formulaire ou sur certaines zones de la page.
Traditionnellement les textes supports de lien étaient écrits en bleu et soulignés et les images cliquables étaient encadrées par un liséré bleu. Ce bleu se transformant en violet si le lien a déjà été activé. Aujourd'hui cette tradition s'est souvent perdue.
Mais on peut repérer un lien en déplaçant le pointeur de souris dans la fenêtre du navigateur. Si le pointeur passe sur un lien il prend la forme d'une main. Cependant cela n'est pas vrai pour les boutons de formulaire mais, dans ce cas, on se doute qu'ils sont là pour être activés.
Il faut savoir aussi que le concepteur de la page peut donner au pointeur de souris n'importe quelle forme, y compris au survol d'un lien. En général, comme les concepteurs de sites ne tiennent pas à transformer leurs pages en jeux de piste, ils conservent les formes conventionnelles du pointeur.
De plus, afin de mieux attirer l'attention, il est possible au concepteur de modifier l'apparence du texte supportant un lien lorsque la souris passe dessus. C'est ce qui est fait sur ce site, les liens textes sont écrits en bleu, au survol du pointeur de souris le texte devient rouge. Il peut en être de même pour les liens sur images : l'image change lors du survol de la souris.
L'activation d'un lien se fait généralement en cliquant dessus avec la souris (un seul clic suffit). Il est possible de le faire au clavier en sélectionnant le lien par la touche de tabulation et en l'activant par la touche "entrée".
Parfois le simple survol de souris active le lien.
Il est souhaitable de le concepteur du site indique ce qui va se passer lorsque le lien sera activé, soit explicitement par le contexte du lien, soit par une "info-bulle" apparaissant près du lien lors du survol souris. Dans la plupart des cas (donc pas toujours) au survol souris d'un lien on voit apparaitre dans la barre d'état (en bas à gauche de la fenêtre du navigateur l'indication de la cible.
Il en existe de nombreuses sortes.
Si l'on s'en tient à ce que signifie le mot lien, c'est bien ce à quoi on
doit s'attendre en activant un lien. La page est remplacée par une autre,
éventuellement sur un autre site.
Sur ce site c'est ce qui se passe en activant les liens du menu en haut de
page.
Parfois on ne se trouve pas en haut de la nouvelle page.
Le lien peut ne pas changer de page mais afficher une autre partie de la
page. Ainsi on évite à l'utilisateur de faire défiler la page.
Sur ce site, les liens présentés en haut à droite sous "Chapitres de ce
document" fonctionnent ainsi.
Pour ces deux types de cibles, les boutons de navigations de la barre d'outils du navigateur (page précédente et suivante) fonctionnent.
Dans ce cas, la page cible est affichée dans une nouvelle fenêtre. Selon la configuration du navigateur ce peut être un nouvel onglet ou une nouvelle instance du navigateur.
Naturellement, le bouton de navigation "page précédente" ne sera pas actif dans la nouvelle fenêtre.
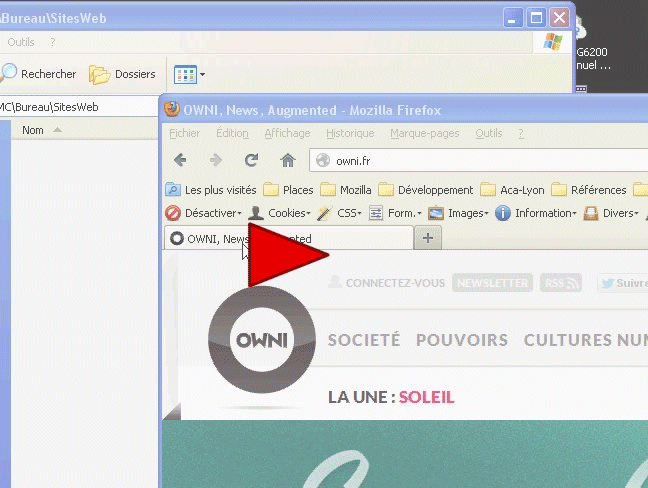
Voici un exemple avec wikipedia (pensez à refermer).
Certains liens conduisent à une cible qui ne peut pas être traitée par le navigateur mais par un autre logiciel. Dans ce cas (mais cela dépend de la configuration du système), le logiciel adapté est lancé pour traiter le lien.
On voit cette action se produire par exemple pour le chargement de documents en format PDF ou pour l'envoi d'un courrier électronique (testez mais n'envoyez pas, l'adresse n'est pas bonne).
Au lieu de lancer un logiciel, certains liens proposent par une boîte de
dialogue le téléchargement d'un fichier sur la machine de l'utilisateur ou
éventuellement de lancer un logiciel de traitement pour ce fichier. On notera
qu'il est possible de configurer le navigateur afin de réaliser l'une de ces
actions par défaut.
Exemple : Téléchargement d'un document PDF
Un lien peut déclencher une action (généralement Javascript) qui sera
exécutée par le navigateur. Là il y a beaucoup de possibilités. Il faut
cependant que le navigateur ne soit pas configuré pour interdire les
scripts.
Ouverture d'une page en
"popup" (pensez à la refermer),
Changement des couleurs (pendant 2
secondes).
On a vu que dans beaucoup de cas, l'activation d'un lien provoque un changement de la page affichée, ainsi l'internaute "navigue" sur le web.
Parfois cette navigation amène à une page qui n'est pas intéressante pour l'utilisateur ou qui ne contient pas de liens utiles. Il peut être intéressant de revenir à la page précédente. Pour cela, il suffit de cliquer sur le bouton représentant une flèche dirigée à gauche situé à gauche de la barre d'outils (la tache clavier "retour arrière" ← produit le même effet), si l'on n'a pas de page précédente, ce bouton est inactif. Si on a reculé ainsi dans les pages, le bouton représentant une flèche droite, à côté du précédent, permet de reprendre le parcours en avançant.
![]() Boutons de navigation dans Firefox 10
Boutons de navigation dans Firefox 10
On remarque donc que le navigateur mémorise le parcours de l'internaute. Il
est donc possible de "sauter les étapes" et de se rendre directement à une
page déjà vue. Pour cela il suffit de faire un clic droit sur la flèche
gauche pour obtenir la liste des pages parcourues et de sélectionner celle que
l'on veut atteindre, sur certains navigateurs cette fonction se réalise en
cliquant sur un petit triangle situé à côté des boutons flèches ![]() .
.
Au lancement du navigateur, celui-ci accède à une page web prédéfinie
(on peut la choisir en configurant le navigateur), il s'agit de la "page de
démarrage". Il est possible d'y revenir à tout moment en cliquant sur le
bouton de la barre d'outils représentant une petite maison![]() .
.
Le bouton représentant une flèche circulaire ou une double-flèche (selon le navigateur) recharge la page actuelle depuis le serveur. Il est utile si la page n'a pas été chargée correctement ou pour les sites d'actualités présentant des pages qui changent fréquemment. La touche F5 réalise aussi cette fonction.
Le bouton contenant une croix arrête le chargement de la page en cours. On l'utilise lorsque le chargement de la page est trop long. La touche "Echap" correspond à ce bouton.
![]() Ces boutons
sont ceux d'Internet Explorer 8
Ces boutons
sont ceux d'Internet Explorer 8
Certains navigateurs récents ne présentent pas deux boutons mais un seul qui change selon le contexte : pendant le chargement il assure la fonction d'arrêt et ensuite la fonction de rechargement.
La page affichée par le navigateur peut être conservée sur le poste de
l'utilisateur.
Elle pourra être consultée hors connexion à l'Internet et dans l'état où
elle était lors de l’enregistrement.
Il peut aussi enregistrer l'adresse de la page afin de pouvoir y revenir facilement. Dans ce cas une consultation ultérieure nécessite l'accès à l'Internet et présentera la page dans son état actuel.
Depuis le menu "Fichier" par la commande "Enregistrer sous...".
Plusieurs types d'enregistrement sont proposés car, généralement, la page est composée de plusieurs fichiers.
Une autre solution pour conserver la page telle quelle est d'en sélectionner tout ou partie puis faire un copier-coller dans un logiciel de traitement de texte.
Dans les deux premiers cas, il suffit d'ouvrir le fichier "HTML" dans son
navigateur pour voir la page. Dans le dernier cas on peut utiliser un éditeur
de texte.
Ici seule l'adresse (URL) de la page est conservée.
Deux méthodes sont possibles.
Voici une méthode assez simple et rapide.
Pour accéder à la page enregistrée, il suffit de double-cliquer sur le raccourci. Le navigateur s'ouvre alors sur la page.
Si le navigateur était déjà ouvert (sur une autre page), soit une nouvelle fenêtre de navigation est créée soit la page s'ouvre dans un nouvel onglet. Cela dépend de la configuration du navigateur.
Dans le cas où plusieurs types de navigateurs sont installés sur le système, le navigateur concerné est celui qui est défini comme "navigateur par défaut".
Une autre méthode consiste à faire glisser le raccourci vers une fenêtre de navigateur (déjà ouverte). Dans ce cas, la page en cours est remplacée par celle du raccourci.
Dans ce cas c'est le navigateur web qui mémorise les adresses de pages.
Selon les navigateurs ces enregistrements sont nommés :
Mais quel que soit le nom, le principe est le même (dans la suite de ce
chapitre, on utilisera le mot "signet").
L'enregistrement de l'adresse de la page peut être réalisé de plusieurs
façons.
Notons que cette dernière méthode est plus puissante car le panneau des
signets facilite l'organisation de ceux-ci par la création de dossiers.
Les signets peuvent aussi être placés dans la barre personnelle du navigateur
(ou barre des favoris, barre des signets) par la même méthode de
glisser-déplacer". Dans ce cas, ils seront facilement accessibles.
L'affichage d'une page enregistrée comme signet se fait facilement en cliquant
sur le nom du signet, soit dans le menu "signets", soit dans le panneau ou par
la barre personnelle.